1. Introduction
어두운 곳에서 객체를 관찰 할 때, 사람 눈으로 관찰하면 잘 보이는데 카메라로 촬영하면 잘 보이지 않는 경우가 있습니다. 조도가 낮은 환경에서 촬영한 영상을 저조도 영상이라고 부르는데, 저조도 영상은 대게 가시성이 떨어지며 대비가 낮고 노이즈가 나타나는 문제가 있습니다. 이러한 저조도 영상에 저조도 개선 기술을 적용하여 가시성과 대비를 개선할 수 있습니다. 저조도 영상 개선 기술은 다양한 분야에 많이 사용됩니다. 소비자들이 저조도 환경에서 아름다운 사진을 촬영할 수 있도록 할 수 있고, 자율 주행 자동차나 비디오 감시 등의 시스템들이 어두운 환경에서 고품질의 영상을 획득할 수 있도록 할 수 있습니다.

저조도 영상 개선 기술은 꾸준히 연구되어 오고 있는데 여전히 개선의 여지가 많습니다. 위 그림은 입력 영상에 따른 기존 방법들과 제안하는 방법의 결과를 보입니다. 기존 방법들은 Histogram equalization이나 Retinex 이론에 따라 저조도를 개선하는데, 대부분 노이즈의 영향을 무시하고 밝기와 대비를 개선하는 데 중점을 둡니다. 노이즈를 고려하는 방법의 경우, 노이즈를 제거하는 파이프라인을 별도로 구성하기도 합니다. 하지만 이 방법은 저조도를 개선하기 전에 노이즈를 제거하면 블러가 되고, 저조도를 개선한 후 노이즈를 제거하면 노이즈가 증폭되는 문제가 있습니다. 이 문제를 해결하기 위해 본 논문에서는 저조도와 노이즈 제거를 동시에 하는 솔루션을 제안합니다. 또, 이 논문에서는 기존의 학습 기반의 저조도 영상 개선 방법에서 사용되는 dataset들은 양이 부족하여 학습하는 데 어려움이 있다고 주장하고 있습니다. 이러한 문제를 해결하기 위해 양질의 저조도 영상 dataset을 구성하는 방법을 제안합니다.
이 논문의 Contribution은 다음과 같습니다.
- Multi-branch network 구조의 attention guided double enhancement 방법 제안
- 저조도와 노이즈와 관련된 attention map을 생성하고, 저조도와 노이즈를 동시에 효과적으로 개선
- 대량의 저조도 영상 dataset을 구성하는 방법 제안
- 다양한 실험을 통해 제안하는 방법이 기존의 방법들보다 우수하며, 다른 task에도 적용이 가능한 유연성을 보임
2. Related work
Traditional enhancement methods
기존 저조도 영상 개선 방법은 Histogram equalization(HE) 기반 방법과 Retinex 이론을 이용한 방법 두 가지로 나눌 수 있습니다. HE 기반 방법은 밝기 값의 통계적 특성을 이용하여 영상의 dynamic range를 확장하거나 영상의 대비(contrast)를 개선하는 방법입니다. 이 방법은 조명(illumination)을 고려하지 않고 영상 전체의 대비를 개선하면서 과도하게 혹은 저조하게 개선하는 현상을 일으킵니다.
두 번째로는 Retinex 이론을 이용한 방법입니다. 영상은 반사(reflectance) 성분과 조명(illumination) 성분으로 이루어져 있다는 가정에 따라 정의된 이론이 Retinex 이론입니다. 영상을 반사 성분과 조명 성분으로 나누었을 때, 외부 요인인 조명 성분을 잘 조정하면 저조도 영상을 개선할 수 있습니다. 이렇게 하기 위해서는 영상의 조명 성분을 잘 추정 해야 하는데, 수학적으로 ill-posed 문제이기 때문에 여러 가지 가정에 따라 조명 성분을 추정하는 게 일반적입니다. 이 과정에서 hand-crafted 방법들이 적용되며, 파라미터 튜닝에 의존적이게 됩니다. 또, Retinex 이론 기반 방법들은 대부분 노이즈를 고려하지 않기 때문에 저조도를 개선 시키면서 노이즈 또한 증폭시키는 문제점이 있습니다.
Learning-based enhancement methods
저조도 영상 개선과 같은 low-level 영상 처리에도 end-to-end network, GAN과 같은 딥러닝 기술이 적용되면서 해당 분야에도 좋은 성과를 보이고 있습니다. Multi-layer perceptron auto-encoder를 이용한 LLNet, Retinex 이론과 convolution neural network(CNN)를 이용한 RetinexNet 등 CNN 기반의 저조도 영상 개선 방법들이 계속 연구되어오고 있습니다.
또, end-to-end 형태로 구성된 네트워크와 perceptual loss를 이용하여 모바일 카메라에서 촬영한 영상을 DSLR 카메라에서 촬영한 품질로 변환하는 DPED 방법, 센서로부터 획득한 raw 영상을 CNN에 바로 입력시켜 영상을 개선하는 방법 등이 있습니다. 이러한 학습 기반 방법들은 학습하는 과정에 노이즈를 제거하는 과정을 포함하지 않거나, 기존 노이즈 제거 방법을 따로 적용하기도 합니다.
Image denoising methods
노이즈를 제거하는 방법 역시 마찬가지로 딥러닝 기술이 적용되면서 좋은 성과를 보이고 있습니다. Gaussian 노이즈를 고려한 BM3D, DnCNN 방법, Poisson 노이즈를 고려한 NLPCA 방법, Gaussian-Poisson 노이즈를 함께 고려한 CBDNet 방법 등이 있는데, 이러한 방법들을 저조도 개선 기술에 바로 적용하게 되면 블러한 결과를 얻게 되는 문제점이 있습니다. 이러한 현상을 피하고자 본 논문에서는 저조도와 노이즈를 동시에 개선하는 방법을 제안합니다.
3. Dataset
Real-world에서 대량의 {저조도 영상, 적정 조도 영상} 쌍 dataset을 구성하는 것은 어려운 일입니다. 기존에는 적정 조도 영상의 밝기 값을 조절하여 저조도 환경을 인위적으로 합성하거나, 카메라의 노출 정도와 ISO 값을 조절하여 dataset을 구성하는 등의 시도가 있었습니다.
특히 노출 정도와 ISO 값을 조정하는 방법을 이용하여 구성한 dataset은 다양한 저조도 환경에 대응하지 못하는(해당 dataset에서의 테스트에는 좋은 결과를 보였지만 다른 저조도 영상에 적용했을 때 과도하게 개선하여 saturation 되는 등의) 현상이 나타나는 문제점이 있었습니다.
이와 유사하게 극-저조도 환경에서 촬영한 raw 영상과 적정 조도에서 촬영한 영상 쌍으로 dataset을 구성하는 사례도 있었는데, 저조도 영상이 raw 데이터이기 때문에 일반적인 저조도 영상 개선에는 사용하기 어려운 단점이 있습니다. 또 이러한 dataset들은 데이터 양이 비교적 적은 문제점도 있었습니다. 이 논문에서는 PASCAL VOC, MS COCO 등의 널리 사용되는 dataset으로부터 저조도 환경을 합성하는 방법 이용하여 대량의 {저조도 영상, 적정 조도 영상} 쌍의 dataset을 구성하는 방법을 제안합니다.
Candidate Image Selection
학습 dataset에 사용되는 영상은 기본적으로 고품질의 적정 조도에서 촬영된 영상이며, 이러한 고품질 영상에 저조도환경을 합성하여 {저조도 영상, 적정 조도 영상} 쌍을 구성합니다. 이 논문에서는 PASCAL VOC, MS COCO 등의 널리 사용되는 dataset에서 고화질의 적정 조도 영상을 선별하기 위해 아래 3가지 방법을 이용합니다.
- Darkness estimation
적정 조도의 영상을 선별하기 위해 다음과 같은 방법을 적용합니다. 먼저 영상에 super-pixel segmentation을 적용하고, 각 super-pixel의 mean/variance가 일정 threshold보다 높다면 해당 super-pixel의 밝기는 밝다고 판단합니다. 그리고 밝다고 판단된 super-pixel의 수가 85% 이상이면 해당 영상은 적정 조도 영상으로 판단합니다. - Blur estimation
뿌옇지 않고 디테일이 잘 표현된 영상을 선별하는 과정입니다. 영상에 laplacian filter를 적용하고, 그 결과의 variance 구했을 때, 그 값이 500 이상이라면 detail이 잘 표현된 영상으로 판단합니다. - Colorfulness estimation
색표현이 잘 된 영상을 선별하는 과정입니다. no-reference 기반의 색 표현 정도 측정 방법의 하나를 이용하며, 그 값이 500 이상이면 색 표현이 잘 된 영상으로 판단합니다.
Target image synthesis
위의 방법으로 선택한 영상들에 대해 real-world 저조도 상황과 유사하도록 저조도를 합성합니다. 대부분의 기존 방법들은 노이즈를 고려하지 않았는데, real-world 저조도 영상은 밝기가 어두울 뿐만 아니라 노이즈까지 포함되어 있습니다. 저조도를 먼저 합성한 후, 노이즈를 합성합니다.
-
Low-light image synthesis
다중 노출 영상에서의 저노출 영상과, 저조도 영상의 차이를 분석해본 결과, 이 둘은 서로 감마 변환(gamma transformation)의 선형 결합으로 근사 표현된다고 합니다. 감마 변환의 선형 결합 방법은 아래 수식과 같습니다. 이 방법으로 저조도를 합성합니다.$\alpha$와 $\beta$는 선형 변환을 의미하고, $\gamma$는 감마 변환을 의미합니다.

위 그림은 저조도 합성 결과를 검증하는 그림입니다. 그래프는 $YCbCr$의 $Y$채널 히스토그램이며, 저조도를 합성한 영상과 저노출의 영상을 비교했을 때 유사한 것을 알 수 있습니다.
-
노이즈는 카메라 내에서 처리하는 영상처리(Image processing) 파이프라인을 고려하여 real-world 저조도 잡음인 Gaussian-Poisson mixed 노이즈 모델을 이용하여 합성합니다.
$\mathcal{P}(\cdot)$는 variance $\sigma_{p}^{2}$에 따른 poisson 노이즈를 부여하는 함수, $N_{G}$는 variance $\sigma _{g}^{2}$에 따른 additive white gaussian noise, $f(x)$는 camera response 함수, $M(x)$와 $M^{-1}(x)$는 각각 RGB to Bayer 함수와 그 역변환 함수인 demosaicing 함수입니다. 영상 압축은 고려하지 않았습니다.
-
Image contrast amplification
기존 학습 기반 저조도 개선 방법들의 학습 dataset들은 {저조도 영상, 적정 조도 영상} 쌍으로 구성되는데, 이러한 dataset을 이용하여 저조도를 개선한 방법들의 결과를 보면 contrast가 낮은 현상이 나타나기도 합니다(Fig. 9 영상에서 MBLLEN 방법의 결과). 이러한 현상을 해결하기 위해 적정 조도 영상에 contrast amplication 방법을 적용하여 새로운 고품질의 영상을 획득하고 {적정 조도 영상, 고품질 영상} 쌍을 구성하여 추후 언급할 Reinforce-Net에 사용합니다. 고품질의 영상을 얻는 과정(contrast amplication 방법)은 다음과 같습니다. 적정 조도 영상에 gamma transformation의 선형 결합 방정식으로 10개의 다른 노출 영상을 생성하고 하나의 영상으로 합성한 후, 합성된 영상에 L0-smoothing(edge preserving filter 종류 중 하나)을 이용하여 디테일을 개선하고 고품질의 영상을 얻습니다.
4. Methodology
Network architecture
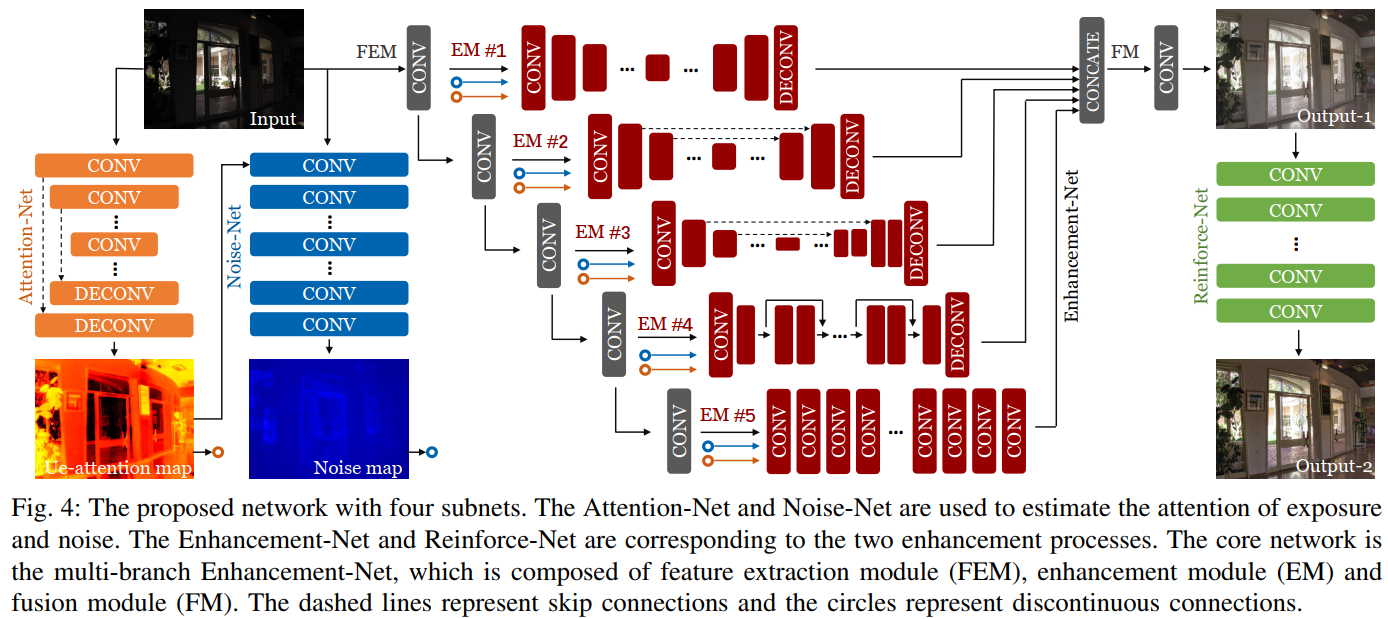
이 논문에서 제안하는 네트워크는 4개의 서브넷 Attention-Net, Noise-Net, Enhancement-Net, Reinforce-Net으로 구성되어 있습니다. 먼저 입력 영상 Input 영상을 Attention-Net에 입력 시킵니다. Attention-Net은 저조도 영역을 추정하는 네트워크입니다. 저조도 영역 Noise-Net은 노이즈 영역을 추정하는 네트워크입니다. 이 두 가지 네트워크로부터 얻은 결과를 보조(guide)로 Enhancement-Net에 이용합니다. 그리고 Reinforce-Net을 통하여 영상을 한 번 더 개선합니다.
-
Attention-Net
Attention-Net은 저조도 영역을 추정하는 네트워크로, 후술할 Enhancement-Net이 저조도 영역에 좀 더 집중할 수 있도록 보조(guide)해주는 ue(under exposure)-attention map을 생성하는 네트워크입니다. ue-attention map은 저조도 영역의 개선이 덜 되거나 과도하게 개선되는 현상을 줄이는 역할을 합니다. Attention-Net의 구조는 U-Net구조로 구성했습니다. ue-attention map은 다음과 같이 구합니다.$max_{c}(x)$는 color채널 중에 최댓값을 반환하는 함수, $R$은 ground truth인 적정 조도 영상, $\mathcal{F}(R)$는 합성한 저조도 영상, $A$는 ue-attention map입니다.

위 사진은 입력 영상에 따른 ue-attention map과 반전된 ue-attention map, 기존 Retinex 이론의 illumination map을 보입니다. 반전된 ue-attention map은 기존 Retinex 이론에서 사용하는 illumination map과 유사한데, 이 내용은 ue-attention map에는 조도 혹은 노출에 관련된 정보가 있다는 것을 의미하고 Attention-Net을 사용하는 이유를 뒷받침해줍니다. 한편, 반전된 ue-attention map을 기존의 Retinex 이론 기반 알고리즘들에 바로 적용하면 만족할만한 결과를 얻을 수 없는데, 그 이유는 기존 Retinex 이론 기반 알고리즘들이 black 영역(pixel 값이 0인 부분)과 노이즈 영역을 다루기 어렵기 때문이라고 주장하고 있습니다.
-
Noise-Net
Noise-Net은 노이즈 영역을 추정하는 네트워크로, Enhancement-Net을 보조해주는 Noise map을 생성하는 네트워크입니다. 영상에서 노이즈는 영상의 텍스쳐 정보와 유사합니다. 일반적인 노이즈 제거 방법을 이용하여 노이즈를 제거하면 텍스쳐 정보도 같이 제거되어 블러가 되곤 하는데, 노이즈 분포를 미리 알고 제거하면 이러한 현상을 줄일 수 있습니다. 이 논문에서는 노이즈의 분포가 조도(illumination)의 분포에 따라 영향이 있다고 주장하고 있으며, ue-attention map을 보조로 Noise-Net을 통과시켜 Noise map을 구합니다. -
Enhancement-Net
Enhancement-Net은 노이즈 제거, 텍스쳐 보존, 컬러 조정 등과 같은 서브 문제를 각각의 네트워크로 구성하여 개선하는 multi-branch fusion 형태의 네트워크로 구성됩니다. Enhancement-Net은 feature extraction module, enhancement module, fusion module 세 가지 모듈로 구성되어 있습니다.-
Feature extraction module(FEM) : FEM은 여러 개의 convolutional layer로 구성되어있습니다. FEM에 입력시키는 영상은 저조도 영상, ue-attention map, Noise map입니다(논문에는 언급이 안 되어있는데, 이 3개의 영상을 concat하여 입력시키는 것으로 예상합니다). 그리고 layer들의 결과는 각각의 enhancement module에 입력시킵니다.
-
Enhancemeht module(EM) : convolutional layer로부터 얻은 5개의 결과를 layer 순서대로 EM #1 ~ #5 에 입력시킵니다. EM들은 U-Net like 구조와 Res-Net like 구조로 구성했습니다.
EM #1 : convolutional/deconvolutional layer로 구성된 구조(U-Net에서 skip connection이 없는 구조)
EM #2, #3 : U-Net like 구조(2와 3의 차이는 중간 layer들의 feature map 크기가 다름)
EM #4 : Res-Net like 구조(batch normalization를 제거하고 몇 개의 res-block들을 사용)
EM #5 : dilated convolutional layer로 구성된 구조(입력과 출력 크기는 같음) -
Fusion module(FM) : EM들의 결과를 concat 하고, 컬러 채널의 dimension으로 출력되는 구조로 구성했습니다.
-
-
Reinforce-Net
Reinforce-Net은 저조도를 개선한 후에도 contrast가 낮게 나타는 현상과 detail을 강조하기 위해 구성한 네트워크입니다. 기존 방법 중에 dilated convolution 구조를 이용하여 효과적으로 영상처리 알고리즘을 구현한 방법이 있는데, 그 방법과 유사하게 네트워크를 구성했습니다.
Loss function
본 논문에서는 영상의 structural information, perceptual information, regional difference를 고려하여 새로운 loss 함수를 제안합니다.
수식에서 , , , 들은 각각 Attention-Net, Noise-Net, Enhancement-Net, Reinforce-Net의 loss 함수이고 , , , 들은 각 loss들의 가중치들입니다.
-
Attention-Net loss
보다 정확한 ue-attention map을 구하기 위해 $l_{2}$-norm을이용하여 구합니다.$I$는 입력 영상(저조도 영상), $\mathcal{F}_{a}(I)$는 Attention-Net이 추론한 ue-attention map, A는 예상되는 ue-attention map입니다.
-
Noise-Net loss
Noise map을 구할 때는 $l_{1}$-norm을 이용하여 구합니다.이고, 는 Noise-Net이 추론한 Noise map, $N$은 예상되는 Noise map입니다. Noise map의 ground truth 영상을 구하는 방법은 논문에 나와 있지 않지만 dataset을 구성하는 단계에서 노이즈를 부여하기 전/후 상황을 이용하여 구할 수 있습니다.
-
Enhancement-Net loss
저조도 영상은 밝기가 낮은 탓에 일반적으로 사용하는 mean square error나 mean absolute error 같은 metric으로 loss를 구하면 블러나 아티팩트가 나타날 수 있다고 합니다. 본 논문에서는 bright, structure, perceptual, region을 고려한 4개의 텀으로 구성된 loss 함수를 설계했습니다.수식에서 , , , 들은 각각 bright loss, structural loss, perceptual loss, regional loss 이고, , , , 들은 각 loss들의 가중치들 입니다.
-
bright loss는 네트워크로부터 추론한 영상이 충분한 밝기를 갖도록 설계되었습니다.
수식에서 $\mathcal{F}_{e}(I,{A}’,{N}’)$는 네트워크로부터 추론된 저조도가 개선된 영상, $\tilde{I}$는 예상되는 적정 조도 영상입니다.
-
structural loss는 영상의 structure 정보를 보존과 블러링을 피하고자 설계되었습니다. 영상의 품질을 측정하는 방법의 하나인 structural similarity(SSIM)의 이론을 이용하여 loss를 구합니다.
수식에서 $\mu_{x}$과 $\mu_{y}$는 픽셀값들의 평균값, $\sigma_{x}^{2}$과 $\sigma_{y}^{2}$는 variance, $\sigma_{xy}$는 covariance, $C_{1}$과 $C_{2}$는 분모가 0이 되는 것을 방지하는 상수입니다.
-
perceptual loss는 고수준의 정보를 사용하여 시각적인 품질 개선하기 위해 설계되었습니다. content loss라고 불리기도 합니다. 이 논문에서는 pre-trained VGG-19 네트워크를 사용했습니다.
수식에서 는 Enhancement-Net으로 부터 추론된 저조도가 개선된 영상, 는 적정 조도 영상을 의미합니다. , , 는 각각 VGG-19 네트워크 feature map의 각각 넓이, 높이, 개수를 의미하고, 는 -th block 안에 있는 -th convolution layer의 feature map을 의미합니다.
-
regional loss는 저조도 영역에 좀 더 주의(attention)하도록 설계되었습니다. 저조도 영역과 저조도 영역이 아닌 부분이 개선되면서 그 개선되는 정도의 균형을 맞추기 위해 아래와 같은 loss 함수를 제안합니다.
수식에서 $ssim(\cdot)$는 위에서 언급한 SSIM loss, ${A}’$는 Attention-Net으로 부터 추정된 ue-attention map 입니다.
-
-
Reinforce-Net loss
Enhancement-Net loss에서 regional loss를 제외한 나머지 3개의 loss로 설계되었습니다.수식에서 , , 는 각각 bright loss, structural loss, perceptual loss를 의미하고 , , , 는 각각 해당하는 loss의 가중치들이며, Enhancement-Net의 해당하는 loss들과 동일합니다.
5. Experimental evaluation
synthetic dataset, real dataset, real images들에 대해 실험을 진행했으며, 실험 결과는 아래와 같습니다.
Experiments on synthetic datasets

위 사진은 저조도와 노이즈를 합성한 영상에 대해 실험 결과 영상들입니다. 노이즈를 고려하지 않은 저조도 개선 방법에는 결과에 최신 노이즈 제거 방법중 하나인 CDBNet을 적용했다고 합니다. 그럼에도 불구하고 제안하는 방법이 노이즈가 적게 보이며, ground truth에 가까운 것을 알 수 있습니다.
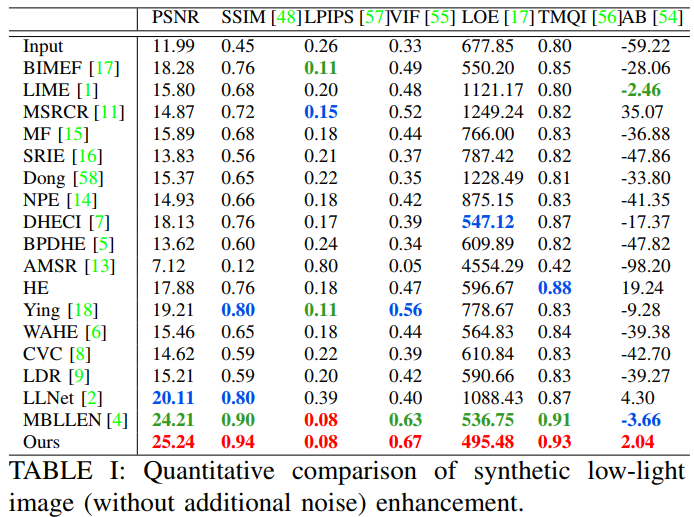
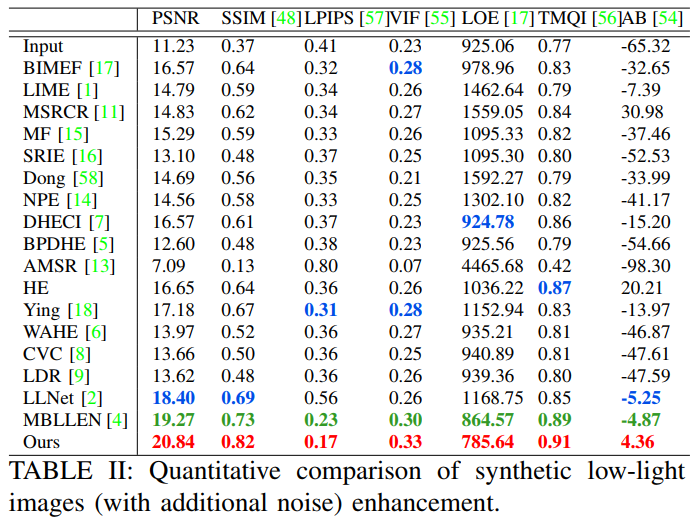
표1, 2는 다양한 성능 평가 방법을 이용하여 객관적 평가한 결과를 보입니다. 표 1은 노이즈를 추가하지 않은 synthetic dataset, 표 2는 노이즈를 추가한 synthetic dataset에 대한 실험입니다. 제안하는 방법의 성능 수치가 가장 높게 나온 것을 알 수 있습니다.
Experiments on real datasets

위 사진은 real-world dataset 인 LOL dataset과 SID dataset에 대한 실험 결과 영상들 입니다. LOL dataset은 한 장면에서 ISO 값을 바꿔 획득한 {저조도 영상, 적정 조도 영상} 쌍으로 구성되어 있고, SID dataset은 한 장면에서 노출 정도를 조절하여 촬영한 {짧은-노출, 긴-노출} 영상 쌍으로 구성되어 있습니다. 단, SID는 raw 데이터 형태로 되어 있습니다. 역시 제안하는 방법이 기존 방법들보다 artifact도 적으며 디테일 밝기 모든 면에서 좋아 보입니다.
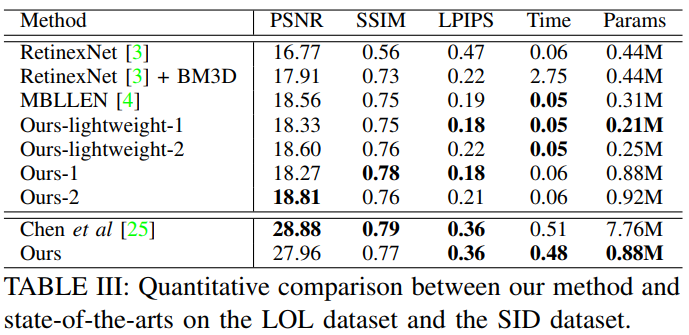
표 3은 LOL dataset 과 SID dataset에 대한 객관적 성능평가 결과를 보입니다. 표에서 두번째 행이 LOL dataset에 대한 평가, 세번째 행이 SID dataset에 대한 평가입니다.
LOL dataset 의 경우 제안하는 네트워크 구조에서 Enhancement-Net의 일부를 수정하여 light weight 버전을 구현하고 비교한 것도 확인할 수 있습니다.
SID dataset의 경우는 raw 데이터로 되어 있어서 실험하기가 까다로운 문제가 있습니다. 기존 방법들은 대부분 raw가 아닌 RGB 영상 형태로 데이터가 입력되어야 하므로 해당 dataset으로 실험할 수 없었습니다. 다만 제안하는 방법과 비교할 때, Chen이 제안한 방법(raw 데이터를 입력하는 방법)에서 네트워크 일부를 Enhancement-Net으로 바꾸어 학습한 후, 객관적 수치를 비교했습니다. 그 결과 제안하는 방법이 PSNR, SSIM의 수치는 조금 낮게 나왔지만 파라미터 수는 낮아 훨씬 가벼운 것을 확인할 수 있습니다.
Experiments on real Images

위 사진과 같이 실제 저조도 환경에서 촬영한 영상에 대한 결과를 보면, 제안하는 방법이 가장 선명하고 자연스러운 것을 확인할 수 있습니다.
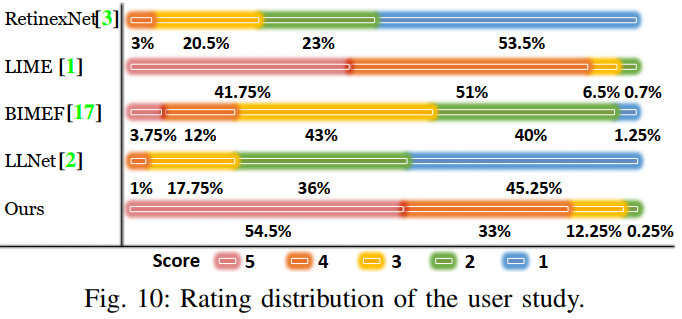
실제 저조도 환경에서 촬영한 영상에 대해 user study를 수행한 결과 제안하는 방법의 점수가 역시 가장 높게 나왔습니다.

위 그림은 흑백 감시 카메라에서 촬영한 영상과 게임 장면에 제안하는 방법을 적용한 결과입니다. 제안하는 방법은 다양한 저조도 환경에도 적용할 수 있다고 주장합니다.

저조도 영상과 저조도를 개선한 영상에 Mask R-CNN 객체 검출 알고리즘을 적용했을 때 결과입니다. 제안하는 방법으로 저조도를 개선 후 객체 검출을 수행했을 때, 객체를 더 잘 검출하는 것을 확인할 수 있습니다.
Ablation study
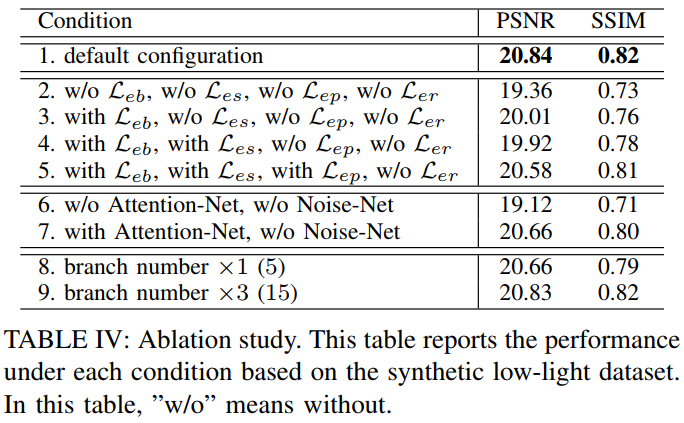
표 4는 본 논문에서 구성한 synthetic dataset 에 대해 ablation study를 수행한 결과입니다. 수행하는 과정에서 Reinforce-Net은 제외했습니다. 2번은 일반적으로 사용하는 MSE loss를 사용했을 때의 결과입니다. 논문에서 제안한 loss를 들을 사용할 때 더 성능이 높은 것을 확인할 수 있습니다. default 구성의 branch 수는 10으로 세팅했을 때의 결과입니다. branch의 수가 높을 때 항상 성능이 좋은 것은 아니라고 언급하고 있습니다.
Unsatisfying cases

위 그림은 제안하는 방법뿐만 아니라 다른 최신의 방법들도 만족할만한 결과를 얻지 못한 경우를 보입니다. 너무 어두워서 texture 정보가 아예 없는 경우, 과도한 압축으로 나타나는 block artifact, 과도한 노이즈 등으로 인해 만족지 못한 결과를 얻는다고 하고 있으며, 추후 이런 문제를 해결할 것이라고 합니다.
Flexible and effective for other low-level image processing tasks

제안하는 방법은 dehazing, super resolution, motion blur 등의 task에도 적용 가능한 유연성을 보입니다.
Conclusion
저조도 개선이라는 주제에서 attention 기법을 사용하는 방법의 예를 알 수 있는 논문이었습니다. Enhancement-Net의 네트워크 구성 형태를 보면 CNN을 통해 얻은 feature들에 다시 CNN을 적용하여 feature를 구하는 multi-branch 형태인데 이렇게도 네트워크를 구성할 수 있겠구나 생각했네요. EM #1 ~ EM #5를 통해 이런 저런 다양한 feature를 뽑아놨으니 알아서 잘 골라봐라 라는 느낌입니다. 아쉬운 점은 기존에 저조도 개선 논문들에서 많이 언급되었던 NASA dataset, Multi-exposure dataset, LIME dataset에 대해 결과 영상을 더 보여줬으면 하는 바램입니다. 긴 글 읽어주셔서 감사합니다.
Reference
Feifan Lv, Yu Li and Feng Lu, “Attention-guided Low-light Image Enhancement,” arXiv preprint arXiv:1908.00682, 2019.